{kind=link}
{kind=link}

From Relation Extraction to Knowledge Graphs - M.Sc. thesis
My master thesis at Iprova. A system for extracting concepts from large corpora and built interactive knowledge graphs to provide invention developers with new insights. View more
I am Diego Antognini, a tech lead and senior AI researcher at Google DeepMind, specializing in multimodal large language models (LLMs). My work primarily involves enhancing these models through iterative feedback and refinement processes. I have 9 years of research experience in natural language processing, machine learning, and recommendation systems.
Additionally, I am a lecturer and module head at the Lucerne University of Applied Sciences (HSLU) where I teach advanced generative AI and deep learning for NLP at the M.Sc. level.
Previously, I was a research scientist at IBM Research and collaborated with the MIT-IBM Watson AI Lab. My research focused on two areas: developing new methods to align large language models (LLMs) and efficient NLP for resource‐constrained training and inference settings. In the first area, my work involved (1) teaching LLMs to transform multi-turn conversations into SQL queries for massive databases; (2) personalizing LLMs according to user preferences; (3) automatically augmenting prompts to steer their behavior; (4) adapting retrieval-augmented LLMs for question-answering systems in the context of scientific literature. In terms of efficient NLP, I built models with a model size in the order of a few megabytes and a latency of a couple of milliseconds with similar performance and higher throughput than large models. Finally, I am also experienced in interpretable models that generate personalized and actionable textual explanations.
I hold a Ph.D. degree in Computer Science from the EPFL, where I conducted research in the AI laboratoy under the supervision of Prof. Boi Faltings. My thesis is titled "Textual Explanations and Critiques in Recommendation Systems" (available here). I developed models to infer high-quality explanations from text documents in a scalable and data-driven manner through selective rationalization. Moreover, I designed models to make textual explanations actionable (referred to as critiquing) and explored two important applications in natural language processing and conversational recommendation systems. I also worked on multi-objective recommendation and multi-document summarization.
Periodically, I give talks such as my work on efficient NLP at MIT-IBM Watson AI Lab or at the NLP Meetup in Zürich where I presented one past work. Additionally, I've appeared on national media when I have participated in challenges with students and won a $10k prize at the IARPA Geopolitical Forecasting Challenge 2018 (press coverage: EPFL News, 24 Heures, RTS Radio (22:25)).
On this website, I present some publications and patents I have been working on and some (prior to Ph.D.) of the most exciting projects.
If you have any questions, feel free to contact me.
For the full list, you can consult my Google scholar profile.
| 32) Learning to Learn from Language Feedback with Social Meta-Learning Paper
Jonathan Cook, Diego Antognini, Martin Klissarov, Claudiu Musat, Edward Grefenstett 2026, COLM 2026 TL;DR: a finetuning methodology that trains LLMs to solicit and learn from language feedback by transforming static tasks into interactive student-teacher dialogues. SML-trained models demonstrate an enhanced ability to solve complex problems over multiple turns. |
| 31) Improving Interactive In-Context Learning from Natural Language Feedback Paper
Martin Klissarov*, Jonathan Cook*, Diego Antognini*, Hao Sun, Jingling Li, Natasha Jaques, Claudiu Musat, Edward Grefenstette 2026, Technical Report TL;DR: a framework that treats interactive in-context learning as a distinct, trainable skill by transforming single-turn tasks into multi-turn "didactic interactions" between a student and a teacher. |
| 30) Position: Introspective Experience from Conversational Environments as a Path to Better Learning Paper
Claudiu Musat*, Jackson Tolins*, Diego Antognini, Jingling Li, Martin Klissarov, Tom Duerig 2026, CoRR TL;DR: robust artificial intelligence reasoning is not merely a product of scaling compute, but emerges from internalizing "introspective experiences" derived from high-quality social and conversational interactions. |
| 29) Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities Paper
..., Diego Antognini, ... 2025, Technical Report TL;DR: we introduce the Gemini 2.X model family: Gemini 2.5 Pro and Gemini 2.5 Flash, as well as our earlier Gemini 2.0 Flash and Flash-Lite models. |
| 28) Trans-LoRA: towards data-free Transferable Parameter Efficient Finetuning Paper
Runqian Wang, Soumya Ghosh, David Cox, Diego Antognini, Aude Oliva, Rogerio Feris, Leonid Karlinsky 2024, NeurIPS TL;DR: We propose a nearly data-free transfer of LoRA modules between models using synthetic data, eliminating the need for original training data. This approach shows effective transfer across various models and tasks, improving performance in many cases. |
| 27) Paraphrase and Solve: Exploring and Exploiting the Impact of Surface Form on Mathematical Reasoning in Large Language Models Paper
Yue Zhou, Yada Zhu, Diego Antognini, Yoon Kim, Yang Zhang 2024, NAACL TL;DR: We investigates how the presentation or surface form of a mathematical problem affects its solvability by large-scale language models. Then, we present Self-Consistency over-Paraphrases (SCoP), which diversifies reasoning paths from specific surface forms. |
| 26) MC Layer Normalization for Calibrated Uncertainty in Deep Learning Paper
Thomas Frick, Diego Antognini, Ioana Giurgiu, Benjamin Grewe, Cristiano Malossi, Rong Zhu, Mattia Rigotti 2023, TMLR TL;DR: A drop-in replacement for Layer Normalization to endow neural networks with calibrated prediction uncertainty. |
| 25) FlowPilot: An LLM-powered system for enterprise data integration
Enrico Toniato, Abdel Labbi, Katya Mirylenka, Christoph Miksovic Czasch, Thomas Gschwind, Paolo Scotton, Francesco Fusco, Diego Antognini 2023, NeurIPS Demo Talk TL;DR: A system to generate training datasets and fine-tune LLMs tailored for customers to convert natural language into SQL queries for massive databases in a conversational manner. FlowPilot ensures the mitigation of errors during both the training and inference, and it can also generates Python code and charts. |
| 24) ESG Accountability Made Easy: DocQA at Your Service Paper
Lokesh Mishra, Cesar Berrospi, Kasper Dinkla, Diego Antognini, Francesco Fusco, Benedikt Bothur, Maksym Lysak, Nikolaos Livathinos, Ahmed Nassar, Panagiotis Vagenas, Lucas Morin, Christoph Auer, Michele Dolfi, Peter Staar 2024, AAAI Demo TL;DR: A question-answering system using large language models and retrieval-augmented generation, designed to generate accurate and relevant answers from a given corpus of domain-specific documents. |
| 23) pNLP-Mixer: an Efficient all-MLP Architecture for Language Paper or Paper
Francesco Fusco, Damian Pascual, Peter Staar, Diego Antognini 2023, ACL TL;DR: An embedding-free MLP-Mixer model for on-device NLP using a projection layer that relies on MinHash and counting bloom filters. Our model occupies merely one megabyte and achieves 99% of the performance of mBERT. |
| 22) Extracting Text Representations for Terms and Phrases in Technical Domains Paper or Paper
Francesco Fusco*, Diego Antognini* 2023, ACL TL;DR: Meaningful word embeddings can be achieved using character-based models that are 5x smaller and 10x faster than BERT-based counterparts and do not suffer from out-of-distribution problems. |
| 21) Assistive Recipe Editing through Critiquing Paper or Paper
Diego Antognini, Shuyang Li, Boi Faltings, Julian McAuley 2023, EACL TL;DR: A framework for generating recipes and enabling users to edit them using critiques in an iterative manner. The system coherently rewrites recipes to satisfy users’ feedback. |
| 20) Towards Workflows for the Use of AI Foundation Models in Visual Inspection Applications Paper
Mattia Rigotti, Diego Antognini, Roy Assaf, Kagan Bakirci, Thomas Frick, Ioana Giurgiu, Klara Janouskova, Filip Janicki, Husam Jubran, Cristiano Malossi, Alexandru Meterez, Florian Scheidegger 2023, Journal (ce/papers) TL;DR: A set of proof-of-concepts workflows using foundation models in visual inspection applications for civil engineering. |
| 19) Unsupervised Term Extraction for Highly Technical Domains Paper or Paper
Francesco Fusco, Peter Staar, Diego Antognini 2022, EMNLP TL;DR: A fully unsupervised method for term extraction that generalizes across domains. Our setup improves predictive performance and decreases inference latency on both CPUs and GPUs. |
| 18) Active Learning for Imbalanced Civil Infrastructure Data Paper or Paper
Thomas Frick, Diego Antognini, Mattia Rigotti, Ioana Giurgiu, Benjamin Grewe, Cristiano Malossi 2022, ECCV Workshop on Computer Vision for Civil and Infrastructure Engineering (CVCIE) TL;DR: A method capable of operating on datasets suffering from heavy class imbalance, achieved by replacing the traditional active learning acquisition function with an auxiliary binary discriminator. |
| 17) Textual Explanations and Critiques in Recommendation Systems Paper or Paper
Diego Antognini 2022, EPFL Ph.D. thesis TL;DR: This dissertation focuses on two fundamental challenges. The first involves generating explanations: inferring high-quality explanations from text documents in a scalable and data-driven manner. The second challenge consists of making explanations actionable, which we refer to as critiquing. This dissertation examines two important applications in natural language processing and recommendation tasks. |
| 16) Positive & Negative Critiquing for VAE-based Recommenders Paper or Paper
Diego Antognini, Boi Faltings 2022, CoRR TL;DR: Fast negative and positive critiquing generalized for variational autoencoders, resulting in up to a 15% higher success rate compared to state-of-the-art models. The key lies in modeling positive and negative critiques as different modalities and employing a multi-modal VAE with weak supervision. |
| 15) Interlock-Free Multi-Aspect Rationalization for Text Classification Paper or Paper
Shuangqi Li, Diego Antognini, Boi Faltings 2022 TL;DR: Addressing the interlocking dynamics of multi-aspect rationalization, utilizing a novel self-supervised contrastive loss and multi-stage training to generate more semantically diverse rationales. |
| 14) Interacting with Explanations through Critiquing (T-RECS) Paper
Diego Antognini, Claudiu Musat, Boi Faltings 2021, IJCAI TL;DR: How to extract explanations significantly preferred by humans over those produced by state-of-the-art models and how to make them actionable; enabling users to interact with them iteratively for improving the recommendation. |
| 13) Fast Multi-Step Critiquing for VAE-based Recommender Systems (M&Ms-VAE) Paper or Paper Video
Diego Antognini, Boi Faltings 2021, RecSys TL;DR: Fast multi-step critiquing generalized for variational autoencoders, resulting in speeds up to 26x faster and a success rate 20% higher compared to state-of-the-art models. The key lies in modeling the problem using multi-modal VAE and weak supervision. |
| 12) Multi-Step Critiquing User Interface for Recommender Systems Paper or Paper Video
Diana, Petrescu*, Diego Antognini*, Boi Faltings 2021, RecSys Demo TL;DR: We propose and demonstrate a new way of interacting with recommender systems to help users make decisions and find their ideal items. |
| 11) Rationalization through Concepts (ConRAT) Paper or Paper Video
Diego Antognini, Boi Faltings 2021, ACL Findings TL;DR: Generalization of MTM: how to extract interpretable multi-faceted concepts (i.e., rationales) for single-task classification problems. It generate concepts that align with human rationalization, and outperforms state-of-the-art methods trained on each aspect label independently. |
| 10) Multi-Dimensional Explanation of Target Variables from Documents (MTM) Paper or Paper Video
Diego Antognini, Claudiu Musat, Boi Faltings 2021, AAAI TL;DR: One model to extract interpretable, meaningful, and coherent multi-faceted rationales for multi-task text classification problems, and perform better than individual rationalization models. |
| 9) Addressing Fairness in Classification with a Model-Agnostic Multi-Objective Algorithm Paper or Paper Video
Kirtan Padh, Diego Antognini, Emma L. Glaude, Boi Faltings, Claudiu Musat 2021, UAI TL;DR: A model-agnostic multi-objective architecture that optimizes multiple fairness notions and sensitive attributes using a novel differentiable relaxation that approximates fairness notions through the hyperbolic tangent function. |
| 8) Multi-Gradient Descent for Multi-Objective Recommender Systems Paper or Paper
Nikola Milojkovic, Diego Antognini, Giancarlo Bergamin, Boi Faltings, Claudiu Musat 2020, AAAI Workshop on Interactive and Conversational Recommendation Systems (WICRS) TL;DR: An efficient stochastic multi-gradient descent approach for multi-objective recommender systems. |
| 7) HotelRec: a Novel Very Large-Scale Hotel Recommendation Dataset Paper or Paper
Diego Antognini, Boi Faltings 2020, LREC TL;DR: A new dataset with 50 million hotel reviews with meta-attributes, user information, and multi-aspect ratings. |
| 6) Recommending Burgers based on Pizza Preferences: Addressing Data Sparsity with a Product of Experts Paper or Paper
Martin Milenkoski, Diego Antognini, Boi Faltings 2021, Recsys Workshop of Cross-Market Recommendation TL;DR: We address data sparsity and generate recommendations in domains where there is limited knowledge about the user preferences. |
| 5) Modeling Online Behavior in Recommender Systems: The Importance of Temporal Context Paper or Paper
Milena Filipovic*, Blagoj Mitrevski*, Diego Antognini, Emma L. Glaude, Boi Faltings, Claudiu Musat 2021, RecSys Workshop on Perspectives on the Evaluation of Recommender Systems TL;DR: Omitting temporal context while evaluating recommender systems leads to false confidence. We propose an evaluation protocol and a model-agnostic training procedure to incorporate temporal context. |
| 4) Momentum-based Gradient Methods in Multi-objective Recommender Systems Paper or Paper
Blagoj Mitrevski*, Milena Filipovic*, Diego Antognini, Emma L. Glaude, Boi Faltings, Claudiu Musat 2021, RecSys Workshop on Multi-Objective Recommender Systems TL;DR: A coordinated multi-objective optimization method in which each objective is optimized using an algorithm similar to the Adam algorithm. |
| 3) GameWikiSum: a Novel Large Multi-Document Summarization Dataset Paper or Paper
Diego Antognini, Boi Faltings 2020, LREC TL;DR: A non-news domain-specific dataset for multi-document summarization that is 100 times larger than commonly used datasets. |
| 2) Learning to Create Sentence Semantic Relation Graphs for Multi-Document Summarization Paper or Paper
Diego Antognini, Boi Faltings 2019, EMNLP Workshop on New Frontiers in Summarization TL;DR: How to leverage universal and domain-sepcific sentence embeddings using a graph structure for multi-document summarization. |
| 1) Dataset Construction via Attention for Aspect Term Extraction with Distant Supervision Paper or Paper
Athanasios Giannakopoulos*, Diego Antognini*, Claudiu Musat, Andreea Hossmann and Michael Baeriswyl 2017, ICDM Workshop on Sentiment Elicitation from Natural Text for Information Retrieval and Extraction (SENTIRE) TL;DR: How to utilize large corpora for improved aspect term extraction using distant supervision. |
| 6-15) To be announced (they have been filed). |
| 5) Layer Normalization for Calibrated Uncertainty in Deep Learning Paper
Thomas Frick, Mattia Rigotti, Diego Antognini, Ioana Giurgiu, Cristiano Malossi 2025 |
| 4) Domain-specificity prediction for natural language processing Paper
Diego Antognini*, Francesco Fusco* 2024 |
| 3) Determining specificity of text terms in application contexts Paper
Francesco Fusco*, Diego Antognini* 2024 |
| 2) Self-supervised term encoding with confidence estimation Paper
Francesco Fusco*, Diego Antognini* 2024 |
| 1) Updating window representations of sliding window of text using rolling scheme Paper
Francesco Fusco*, Diego Antognini* 2024 |
My master thesis at Iprova. A system for extracting concepts from large corpora and built interactive knowledge graphs to provide invention developers with new insights. View more
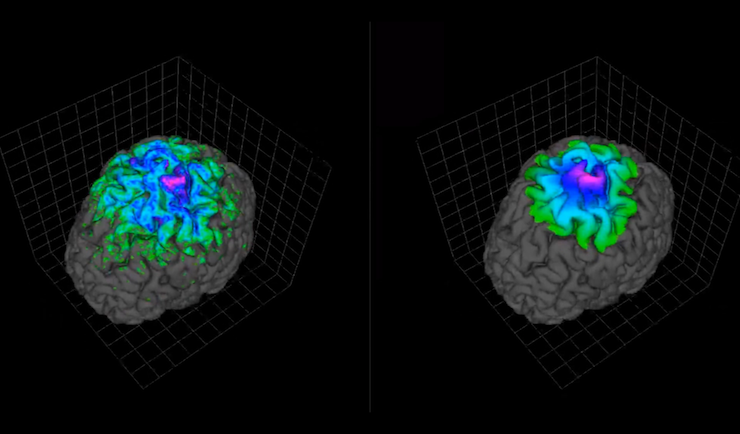
A research project focused on optimizing neuronal activity maps treatment using massively parallel technologies. View more

A scalable, decentralized system that aggregates secondary storage devices in a cluster with the aim of supporting parallel scans of data stored across them. View more

I implemented, tested, analyzed and optimized a flocking algorithm for e-pucks. The objective was for the robots to avoid obstacles within the arena while maintaining their collective formation. Work in a multidisciplinary team. View more
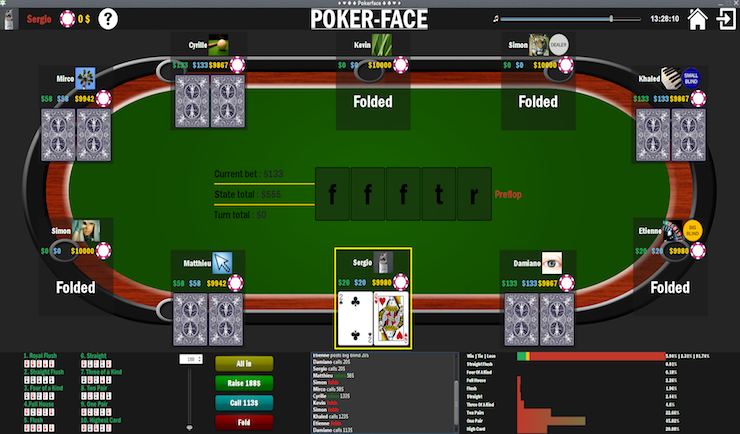
Realization of a complete Texas Hold'em Poker game with artificial intelligence. View more

Shoot 'em up game utilizing motion recognition with Kinect and Wiimotes for spaceship movement, inclination, and shooting. View more

Several mini-projects are available for learning about GPGPU technologies, primarily CUDA. View more

Classifier that recognizes the object present in an image using advanced models. The objects could be classified as a horse, airplane, car, or something else. View more
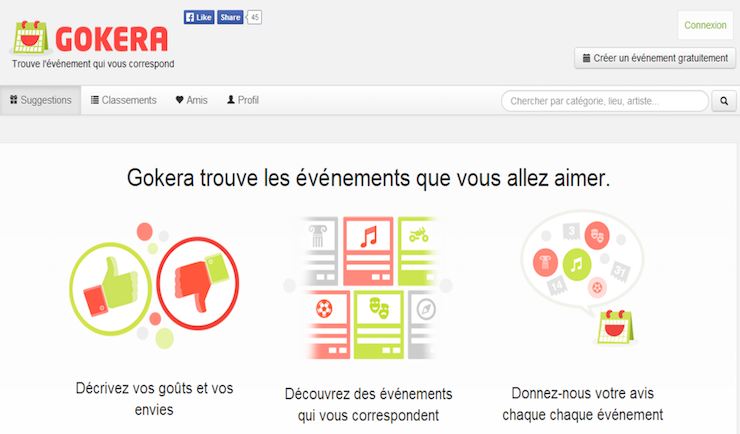
Recommender systems for events based on user data and Facebook profile. View more
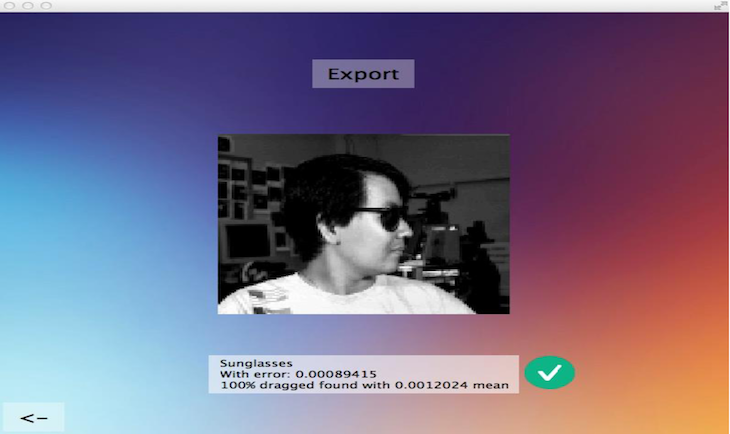
Detect whether a person is wearing sunglasses using a collection of profile pictures of different individuals. Each person has pictures taken from different head angles, displaying different emotions, and with or without sunglasses. View more
Project on regression and classification using linear models. One dataset is provided for each task without any accompanying information. View more
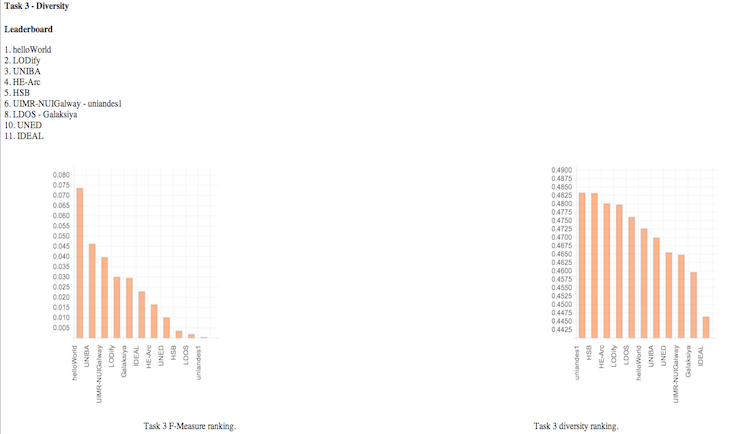
Third task of the challenge of European Semantic Web Conference on a Top-N recommendation of books (ESWC-14 Challenge). Github Report
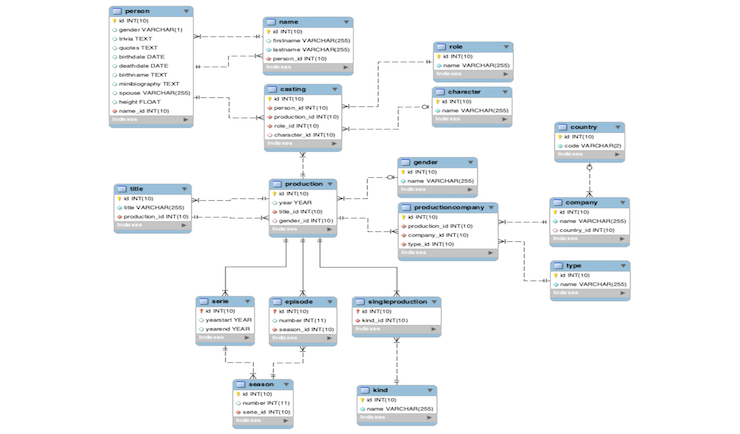
A movie directory with heavy database background using real data from IMDb. View more
Planetarium software displays the current view of the sky at the present location. View more